7주 3일차 TIL 정리

7주 3일차에는 Tableau의 결합된 필드, 집합, VLOD에 대해 학습하였다.
※ 결합된 필드 ※
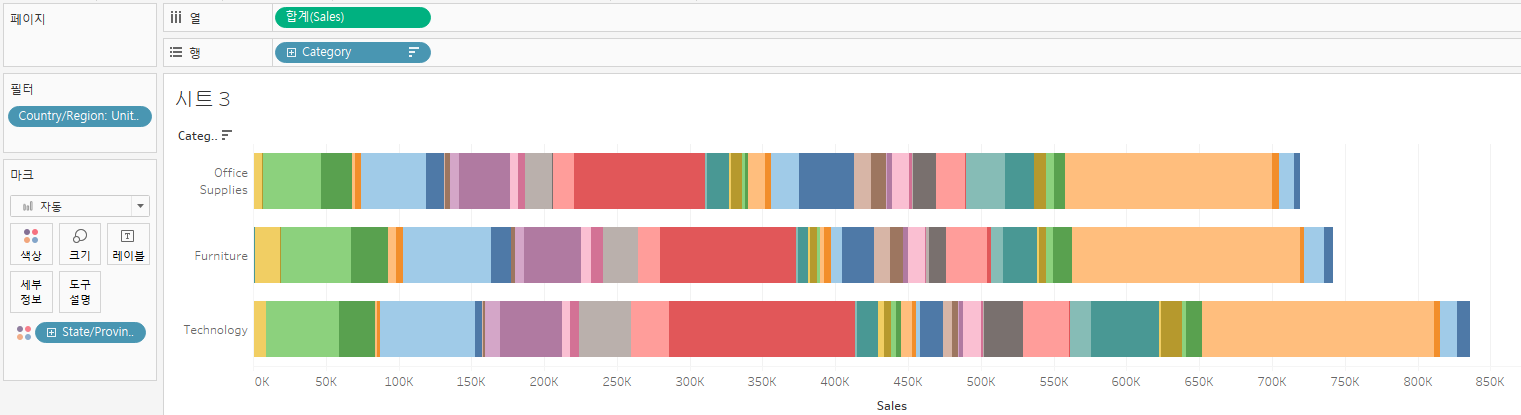
정렬을 해도 전체량을 기준으로만 정렬되고, 지역별 매출순위로 정렬이 안 된다.
같은 주가 같은 곳에, 정렬과 상관없이 배치된다.
이를 해결하기 위해 결합된 필드를 사용한다.
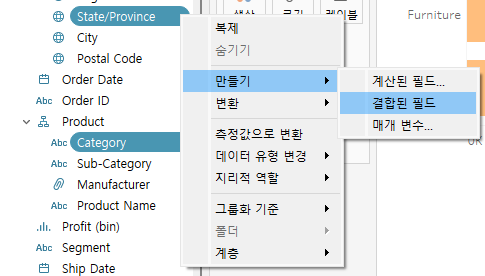
state/province와 category를 기준으로 정렬하므로, 두 개를 기준으로 결합된 필드를 만들어준다.
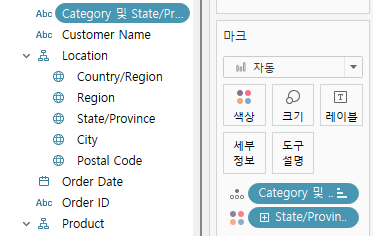
category 및 state/province로 만든 결합된 필드를 세부정보에 넣는다.
(결합된 필드가 색상 위에 위치해야한다.)
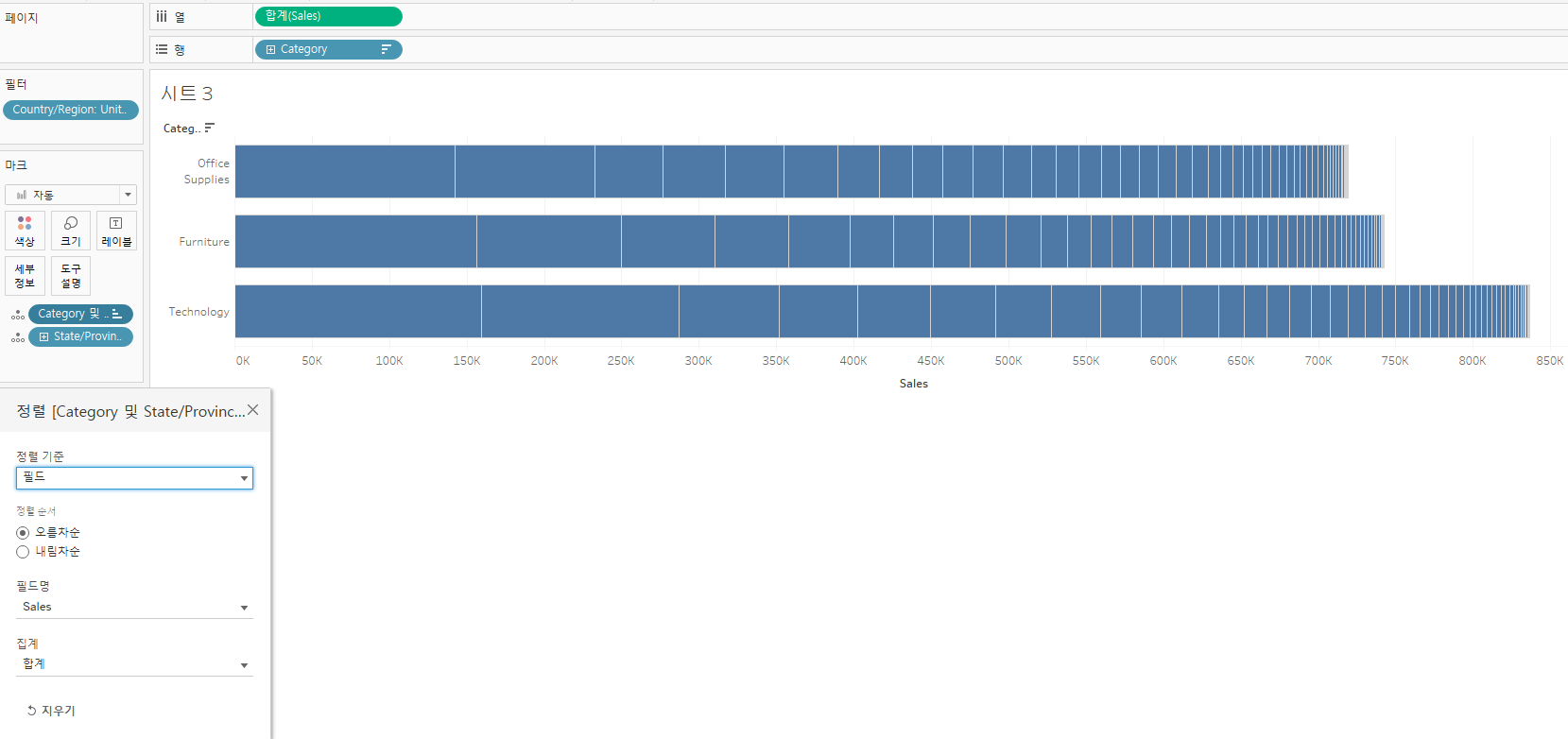
크기순 정렬된 것을 확인, state/province를 색상에 넣은 후 다시 밑으로 내려준다.
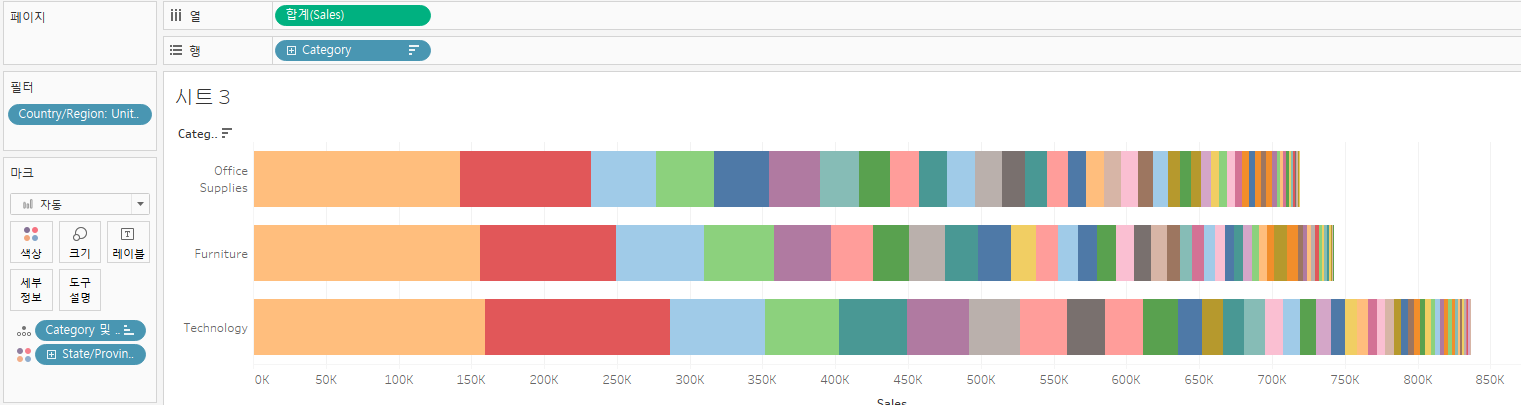
원하는 대로 카테고리별 최대매출 지역 순으로 정렬됐다!
- 언제 결합된 필드는 써야 하는가?
정렬을 눌렀을 때 세부위치가 전혀 변하지 않을 때!
※ 집합 ※
1. 집합을 만들고 매개변수로 컨트롤하기
집합을 컨트롤할 매개변수 생성
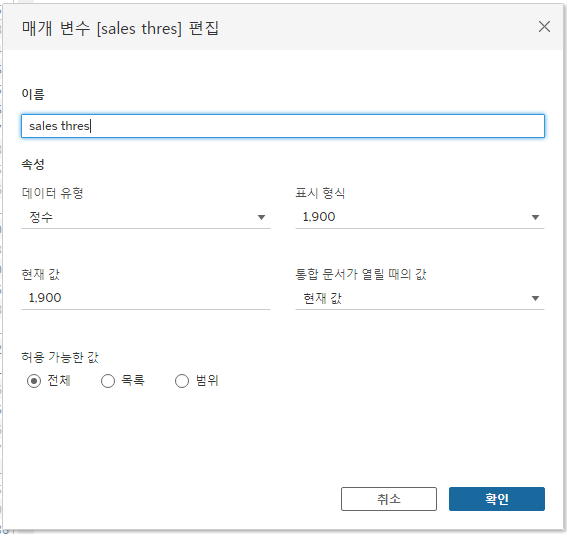
집합 생성
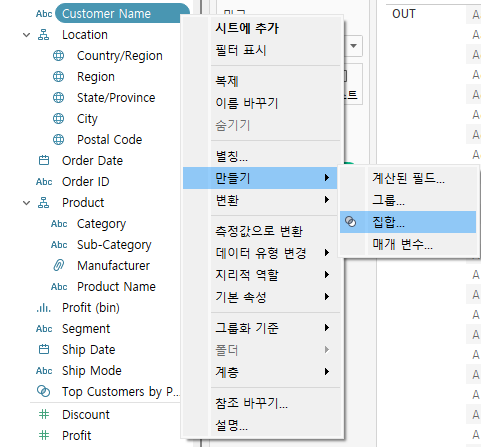
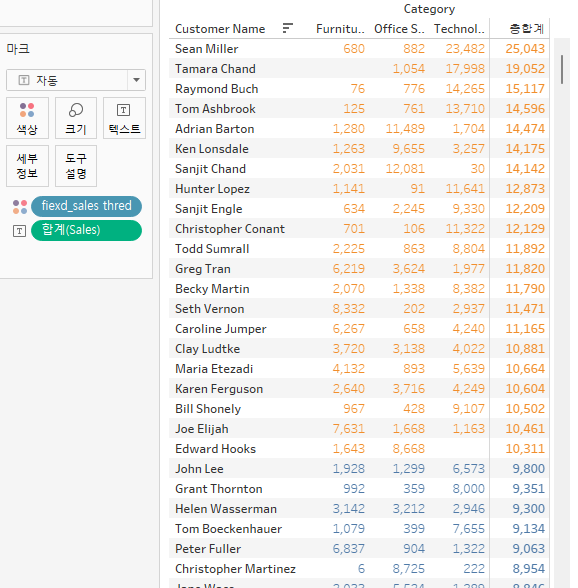
기준으로 삼을 것(예시에선 customer name)을 기준으로 만들기 - 집합 클릭
- 이때 기준으로 삼은 데이터셋 이름을 집합명에 유지해둘 것.(나중에 관리 힘들다!)
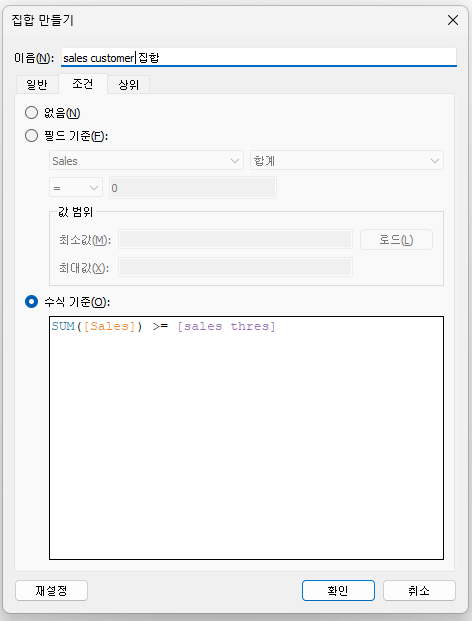
매출합이 sales보다 큰 것들과 아닌 것들을 분류하고자 한다.
만든 집합을 색상에 넣은 후
sales thres를 컨트롤해 집합이 적용되는지 확인해본다.
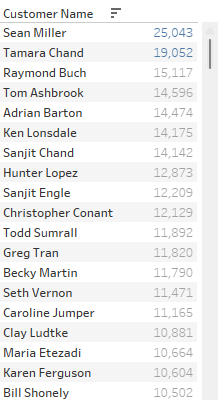
행에도 넣으면 IN / OUT으로 나눠진다.

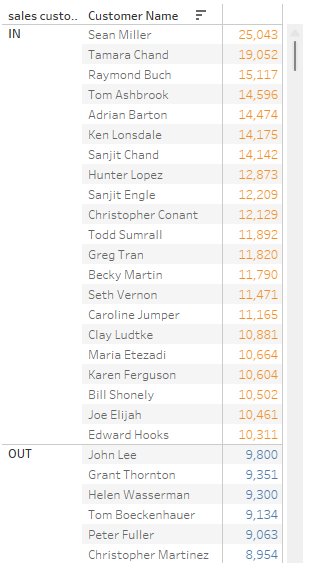
sales thres를 10000으로 조정하면 다음과 같이 집합의 포함범위가 바뀐다.
2. 집합의 특성
집합 안에 사용한 함수 그대로 입력한 계산된 필드를 생성해준다.
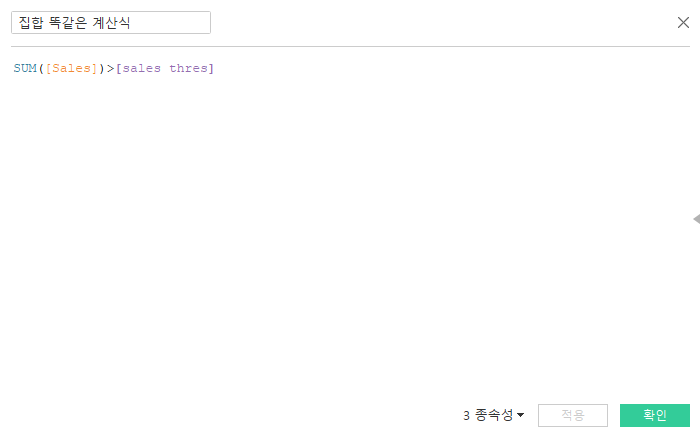
sales thres를 10000으로 설정했을 때, 똑같은 모습으로 결과가 노출되는 것을 확인할 수 있다.
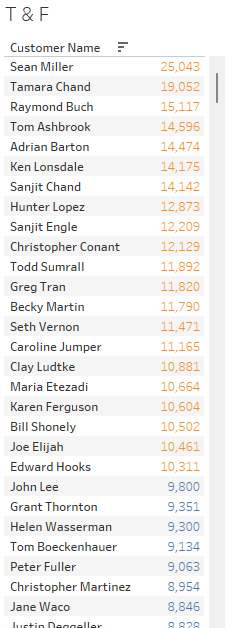
이때, 열에 카테고리를 추가하고 확인해 보자.
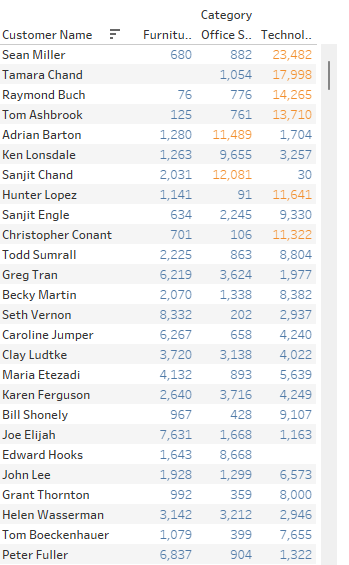
무언가 어그러진 것을 볼 수 있다.
VLOD(Level of Detail)에 영향받아, 카테고리로 세분화되지 않은 고객의 합계매출에서 계산한 값이 무시되고 세부단계에서 10000이상의 값만 표시하고 있다.
이때, VLOD를 무시하고 고객의 합계매출에 따라 계산하고 싶을 때에 집합을 사용하면 된다.
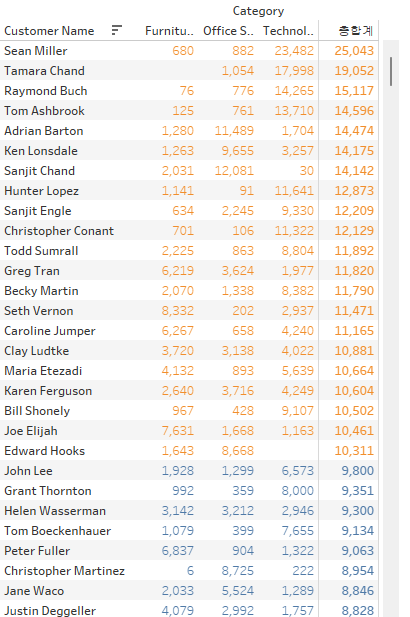
집합을 사용하여 같은 동작을 수행했을 때, 하위 항목이 10000을 넘지 않아도 포함조건으로 넣어 주황색으로 컬러링된 것을 볼 수 있다.
이는 집합을 형성할 때에 고정해둔 VLOD가 Customer Name이기 때문이다.
Cagegory에서 확장해 sub-Category까지 들어가도 결과는 변하지 않는다.
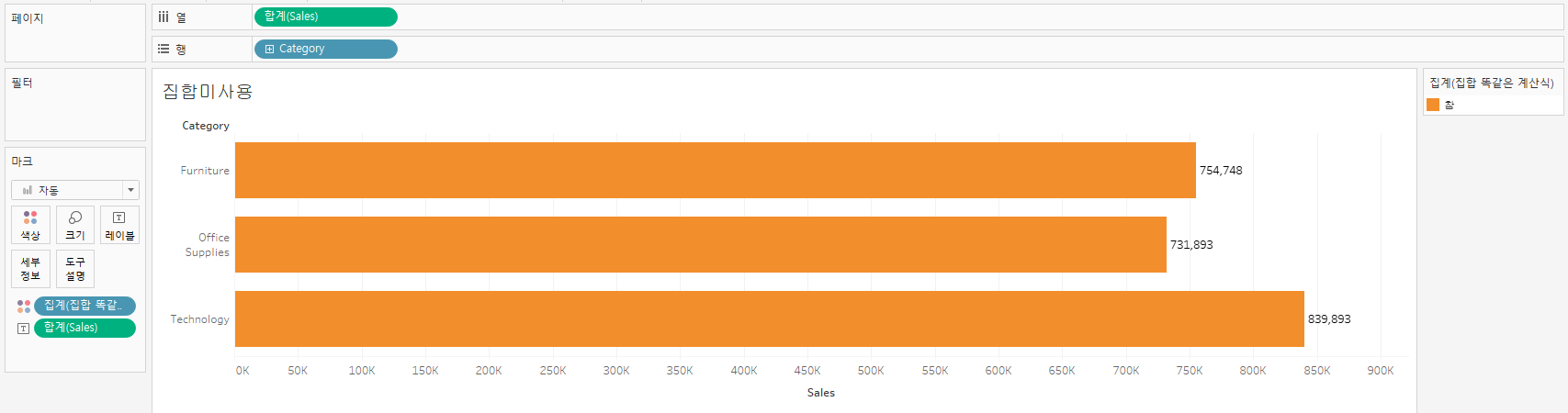
4. 그래프로 확인
집합을 사용하지 않고 계산된 필드로 진행한 것을 카테고리와 sales로 표현해 그래프로 나타내면 다음과 같이 mass값이 나온다.
이때, 전체 구매 중 매출이 10000이하인 고객이 구매한 비율을 보고 싶다면 마찬가지로 집합을 응용할 수 있다.
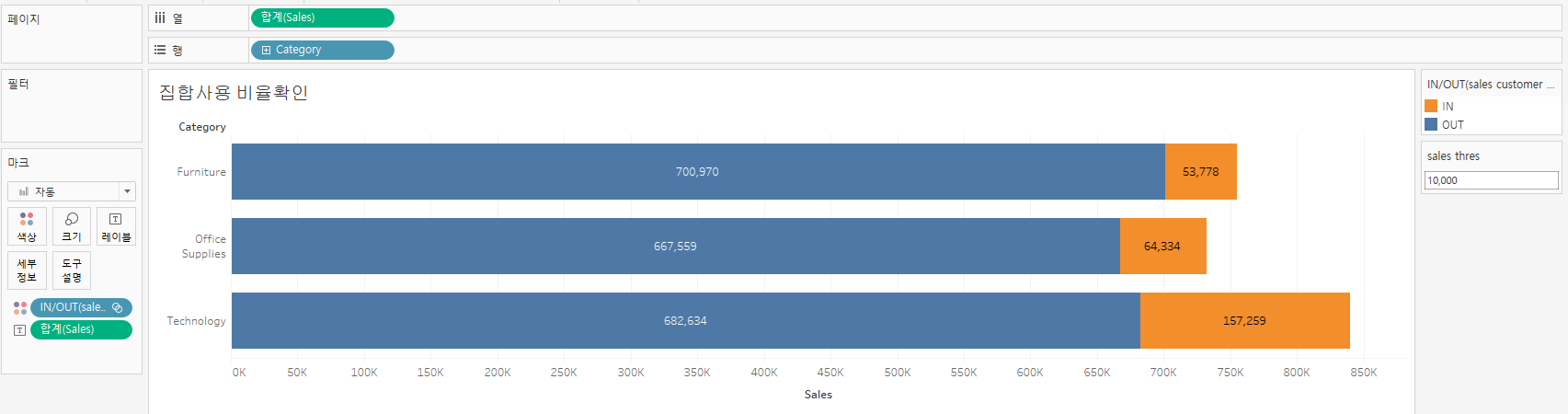
집합을 색상에 넣은 후,
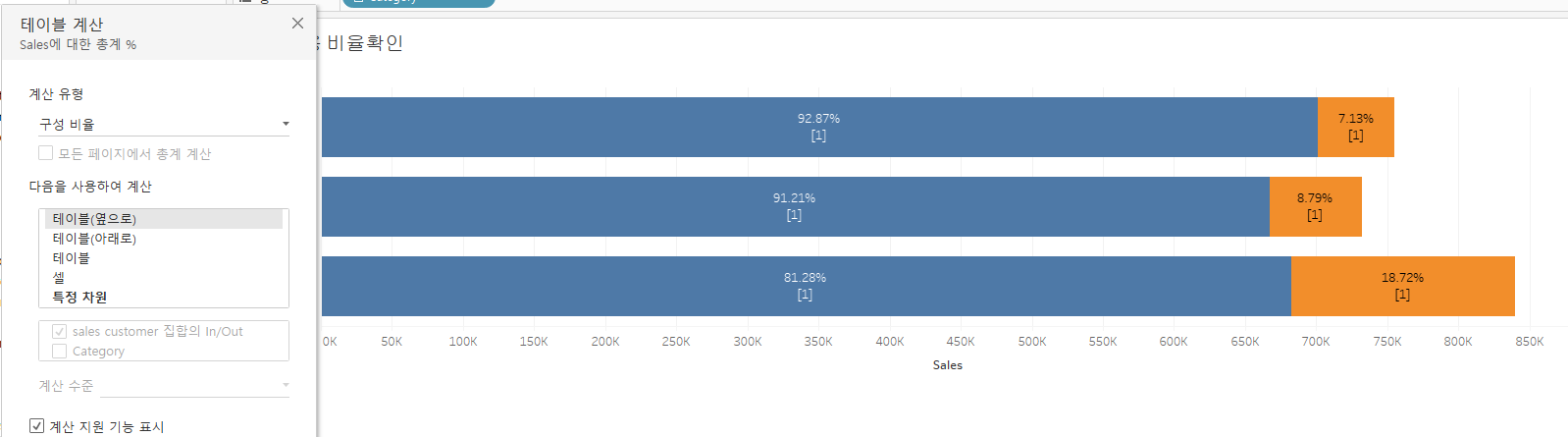
테이블 계산을 활용해 다음과 같이 손쉽게 구성비율을 표시할 수 있다.
3. FIXED (뒤에서 더 다룰 것)
집합을 사용하지 않고 계산된 필드를 사용한 위의 예시에서, 집합과 비슷한 결과를 얻을 수 있는 방법 또한 존재한다.
이떄 사용할 수 있는 것이 FIXED이다.
{ FIXED [Customer Name]: SUM([Sales]) >= [sales thres] }FIXED는 VLOD를 고정한 채로 계산을 수행하는 것이다.
FIXED 이후 오는 [Customer Name] 을 통해 Customer Name 레벨에서만 해당 계산을 수행할 것임을 말해준다.
다음과 같이 계산된 필드를 만든 후 색상을 대체해 주면, 집합과 동일한 결과가 나오는 것을 볼 수 있다.
하지만, 이러한 방법은 일일히 지정해야 하기 때문에 자동화에 무리가 있고, 집합의 기능은 fixed와 필터를 합친 것과 같으므로 fixed는 집합의 하위이다. fixed만으로 수행할 수 있는 집합 대체작업은 한계가 있기 때문에, 집합을 사용하는 것이 합리적이다.
※ VLOD 함수 ※
1. VLOD
- 차원으로 조절 가능하다
- 열, 행, 색상, 크기, 텍스트, 세부정보, 필터에서 조정 가능하다.
→ 왼쪽 최하단 마크 개수가 바뀌면 그게 VLOD의 변경을 말한다.
2. INCLUDE
INCLUDE는 다음과 같은 형태로 계산된 필드에서 사용한다.
{ INCLUDE [Sub-Category]:AVG([Sales]) }하위 범주에서 매출평균을 낸 후, 이를 적용한다. → sub-category를 raw data로 지정해준다고 생각
+ 하위범주의 것을 상위범주로 가져온다!!
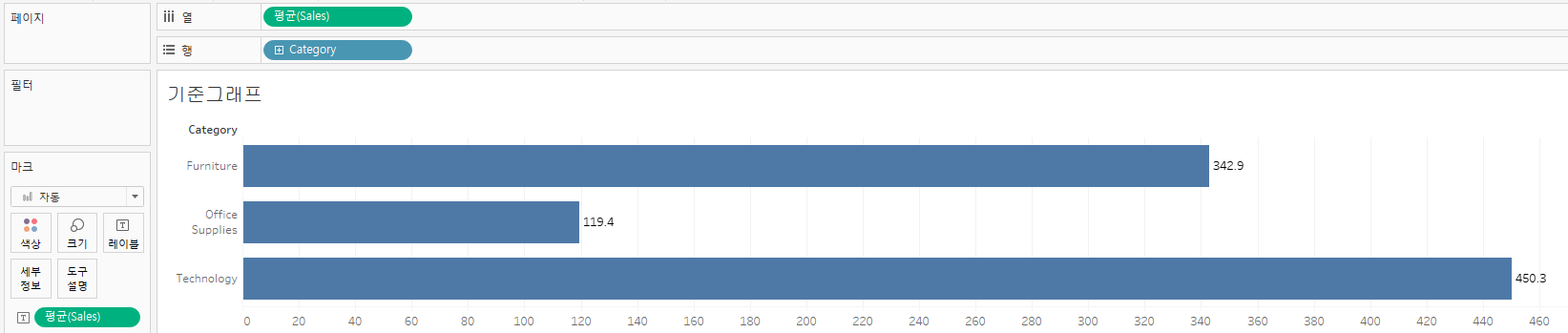
해당 그래프를 통해 개념을 파악해보자.
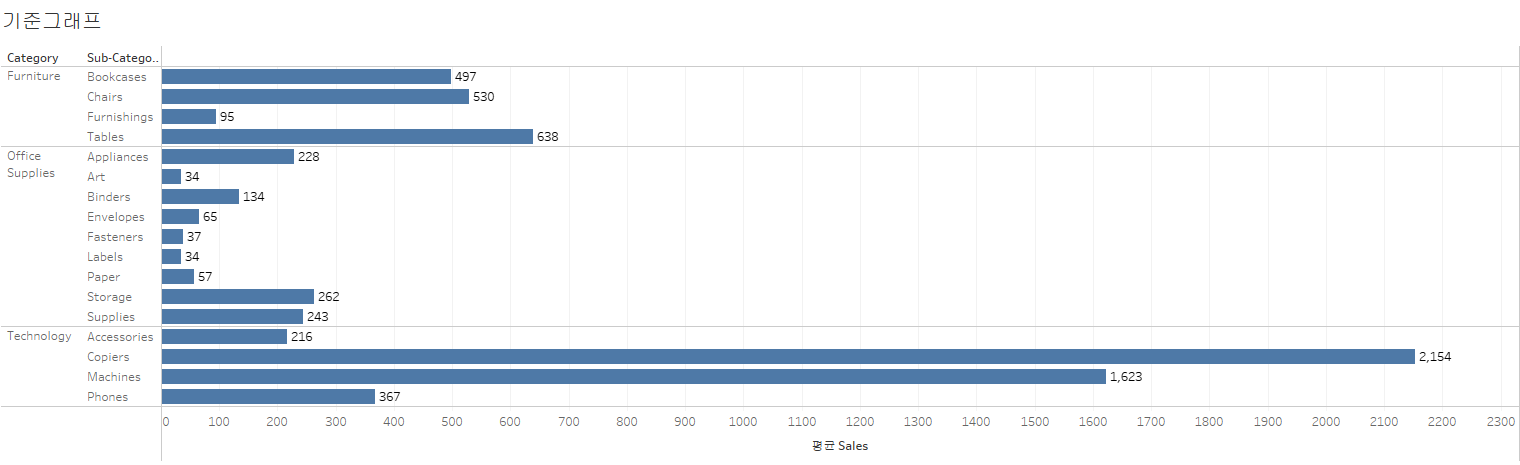
카테고리별 평균을 계산하는 다음 그래프에서 카테고리를 범주화하면, 다음과 같이 노출된다.
이때 이뤄지는 작업은 다음과 같은 순서이다.
1. 데이터 원본(기본으로 설정된 RAW DATA)로 되돌아간다
2. category를 기준으로 그룹을 형성한다
3. 각 그룹 내 모든 요소를 기준으로 평균을 집계한다
이때, 위의 INCLUDE식:
{ INCLUDE [Sub-Category]:AVG([Sales]) }을 적용해 열에 놓아보자.
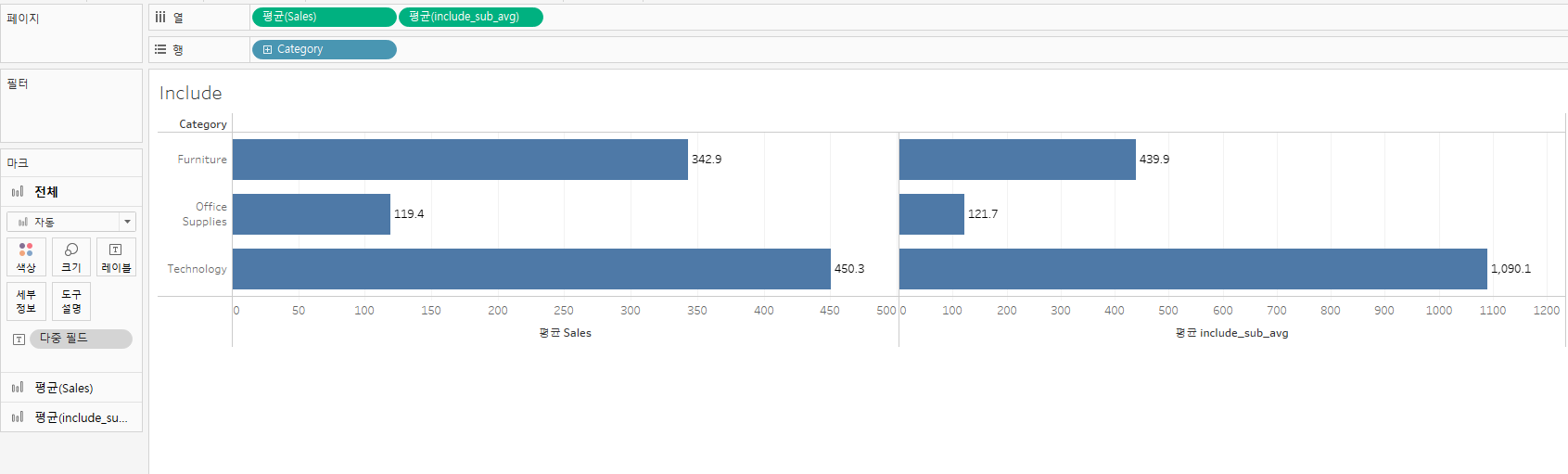
텍스트레이블에까지 넣어 확인해 봤을 때, 다른 값이 나오는 것을 확인할 수 있다.
그 이유는 좌측의 그래프가 위에 언급한 1, 2, 3의 프로세스를 따르는 반면,
INCLUDE를 이용한 그래프는 1번에서 이동하는 RAW DATA의 위치가 데이터 원본이 아닌 sub-category이기 때문이다.
다시 말하자면 sub-category에 집계된 평균을 기준으로 집계하는 것이다.
예시를 들어 다시 설명하겠다.
category1 = ( sub-category1(d1, d2, d3), subcategory2(d4, d5, d6) )
category2 = ( sub-category1(d7, d8, d9), subcategory2(d10, d11, d12) )
이때, 좌측의 그래프는 다음과 같은 값이다.
category1 → (d1+d2+d3+d4+d5+d6) / 6
category2 → (d7+d8+d9+d10+d11+d12) / 6
반면 우측의 그래프는 다음과 같이 수행된다.
category1 → ( (d1+d2+d3)/3 + (d4+d5+d6)/3 ) / 2
category2 → ( (d7+d8+d9)/3 + (d10+d11+d12)/3 ) / 2
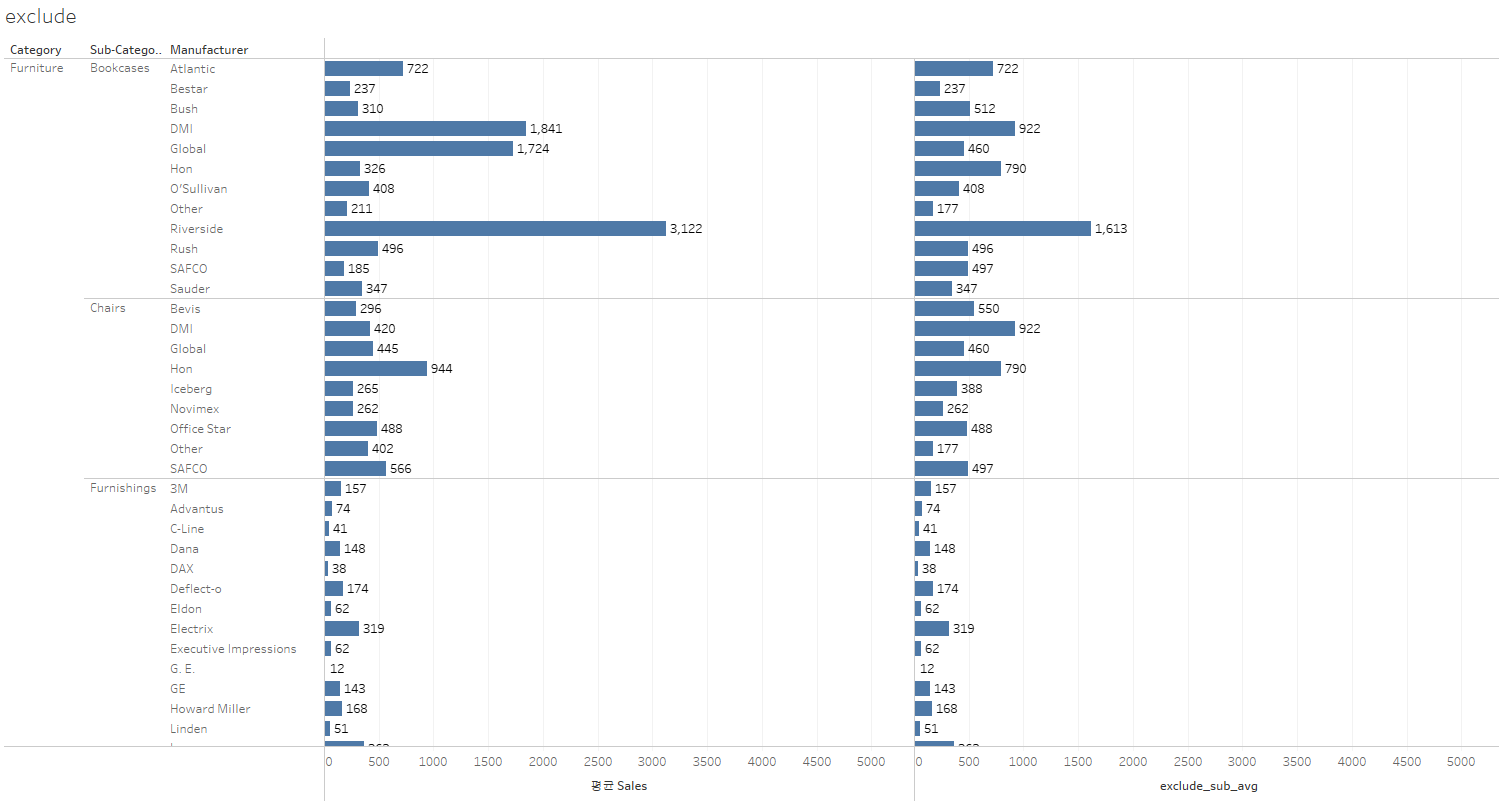
2. EXCLUDE
EXCLUDE는 INCLUDE와 동일한 형식으로 계산된 필드에 사용된다.
{ EXCLUDE [Sub-Category]:AVG([Sales]) }INCLUDE 함수가 하위의 함수를 상위로 가져오는 것이라면,
EXCLUDE 함수는 상위의 함수를 하위로 가져오는 것이다.
이번에도 같은 그래프를 가져와 개념을 파악해보자.
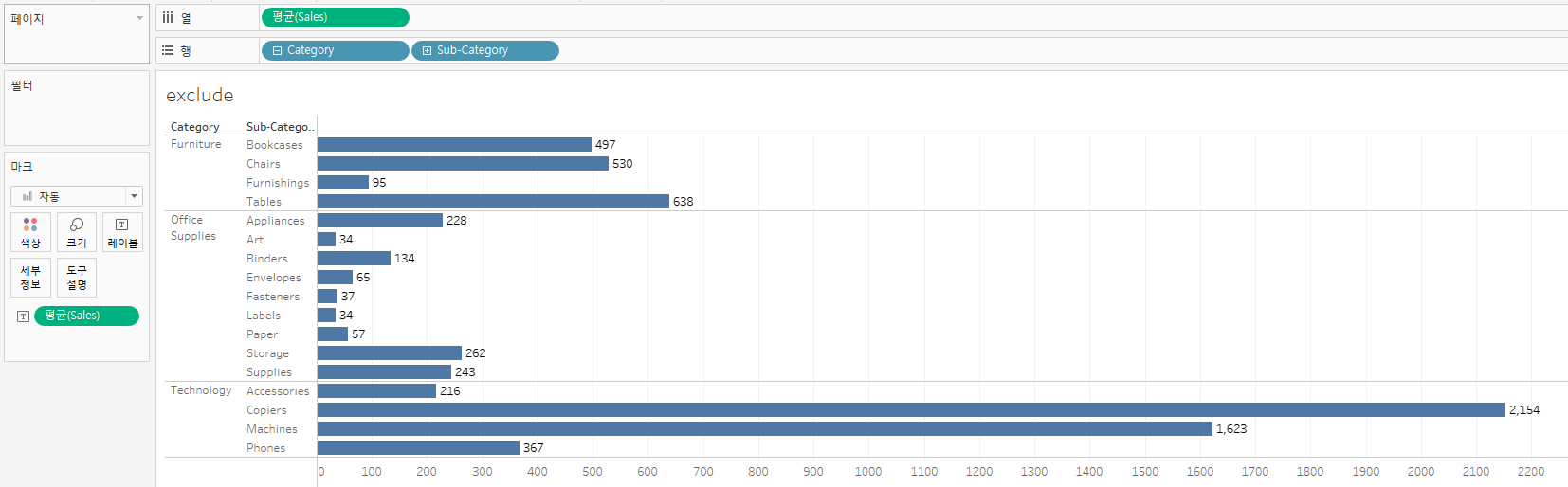
사용했던 그래프에서 카테고리를 sub-category까지 확장하면 다음과 같이 나온다.
이때 열에 만들었던 exclude함수를 삽입하면 결과는 다음과 같다.
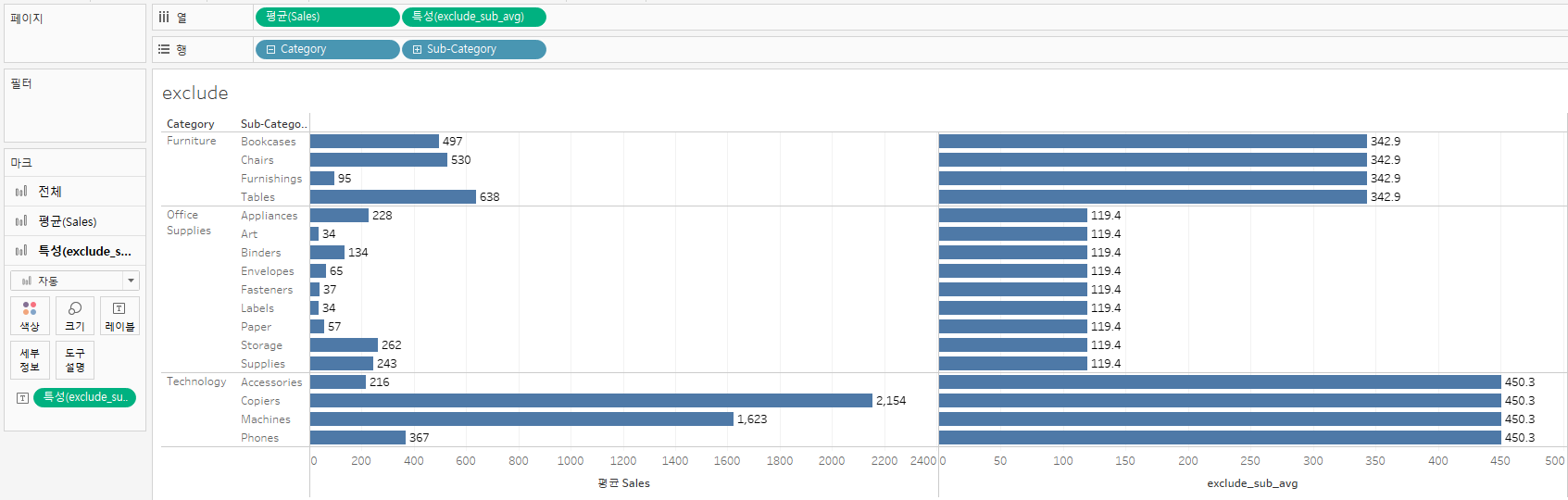
동일한 한 가지 값으로 채워진다.
해당하는 숫자는 상위의 평균값인 카테고리의 AVG([Sales])값이다.
EXCLUDE에 지정된 sub-category데이터셋이 제외(exclude)되면서 그 상위에 있는 값을 불러오는 것이라 할 수 있다.
따라서, sub-category에서 더 하위까지 내려가면 제외되지 않은 데이터인 만큼, 좌측 그래프와 동일한 값이 노출된다.