6주 4일차 TIL 정리

6주 4일차에는 Tableau 프로젝트 기반 강의의 네 번째 수업을 진행했다.
airbnb 과제에 대한 재피드백과 날짜함수에 대한 간단한 수업을 진행한 후 프로젝트를 수정 및 대시보드 설명을 작성하는 과제를 수행했다.
※ DATE 함수 연습 ※
1. DATEADD(date_part, interval, date)
date 에 date_part 단위의 interval을 더함
DATEADD('day', 19, #2022-01-03#)
2. DATEDIFF(date_part, date1, date2, [start_of_week])
date1(시작일)과 date2(종료일) 사이의 간격을 date_part 단위로 구함
이때 [start_of_week]는 선택사항이며, 'sunday' 로 지정 시, 일요일이 주의 첫번째 요일로 고려함
DATEDIFF('day', #2023-01-01#, #2023-01-22#)
3. DATENAME(date_part, date, [start_of_week])
date의 date_part를 문자열로 반환
DATENAME('month', #2023-01-22#)
4. DATEPART(date_part,date,[start_of_week]
date의 date_part를 정수형으로 반환
DATEPART('month', #2023–01–22#)
5. DATEPARSE(date_format, [date_string])
date_string(문자열)을 date_format의 형태(날짜형)로 반환
DATEPARSE('MM-dd-yyyy', '09-20-2021')
6. DATERUNC(date_part, date, [start_of_week])
date 기준 date가 속한 date-part 의 첫째 날 반환
DATETRUNC( 'month', #2023-01-22# )
DATETRUNC( 'quarter', #2023-06-14# )

7. ISDATE(string)
string(문자열)이 유효한 날짜면 true 반환
ISDATE('August 4,2021')
8. MAKETIME(hour, minute, second)
시,분,초로 구성된 날짜값 반환
MAKETIME(16,24,00) = #16:24:00#
9. MAX(expr1, expr2)
a와 b의 최대값 반환(동일한 유형이어야 함, 둘 중 하나라도 Null 이면 Null 반환)
MAX(#2021-01-22#,#2022-01-22#)
10. MIN(expr1, expr2)
a와 b의 최소값 반환(동일한 유형이어야 함, 둘 중 하나라도 Null 이면 Null 반환)
MIN(#2021-01-22#,#2022-01-22#)
11. YEAR(date)
주어진 날짜를 연의 정수로 변환
YEAR(#2022-01-22#)
12. MONTH(date)
주어진 날짜를 월의 정수로 반환
MONTH(#2022-01-22#)
13. WEEK(date)
date의 날짜 주를 정수로 반환
WEEK(#2022-01-22#)
14. DAY(date)
date의 날짜 일을 정수로 반환
DAY(#2022-01-22#)
15. QUARTER(date)
date의 분기를 정수로 반환
QUARTER(#2022-01-22#)
16. TODAY()
현재 날짜 반환
DAY()
※ 프로젝트 피드백 ※

1. '지역별 가격 중앙값' 필드가 필터로 사용되는 것에 대한 직관성이 떨어진다.
2. 연도 단위 필터링이 규모가 너무 큰 감이 있다. 이러한 정보는 연도로 판단하기는 힘들 것 같으니, 분기별 필터링이 더 옳은 선택일 것 같다.
3. 어렵거나 배경지식 등으로 활용되는 그래프는 캡쳐해서 보고서에 미리 설명하고 넘어가야 한다.
※ 피드백 적용 결과 ※
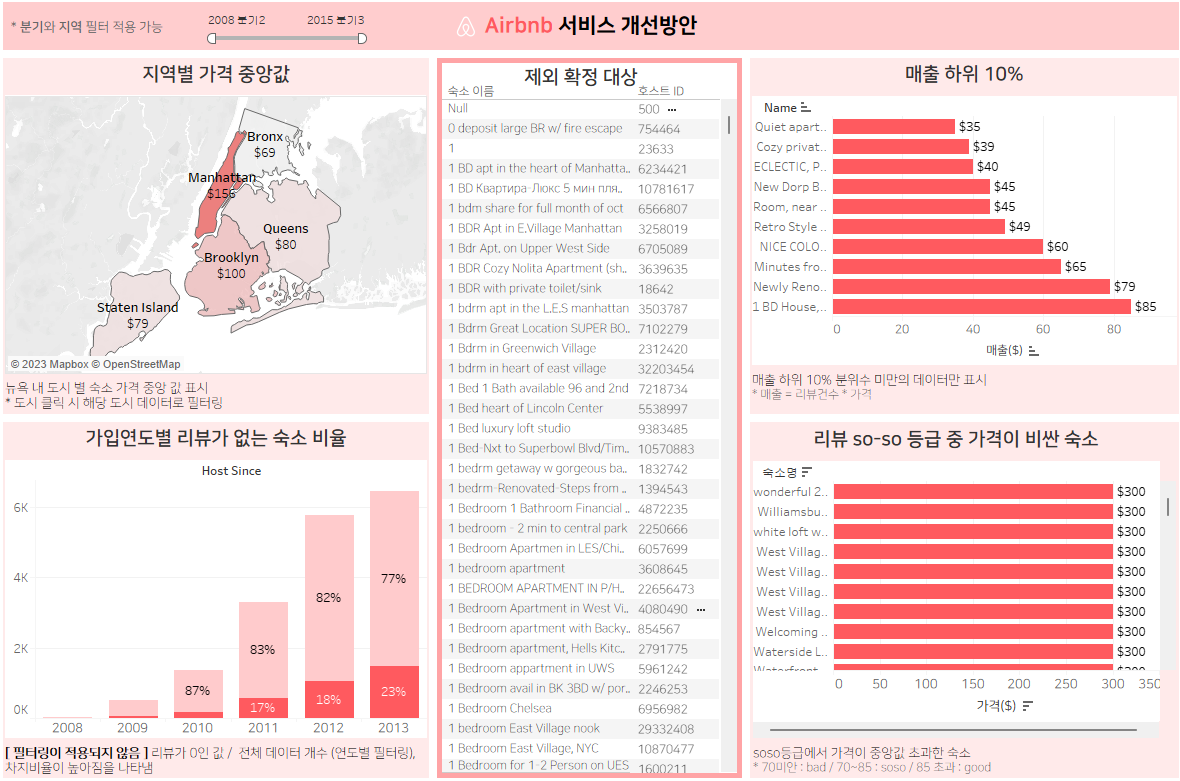
1. 시선이 처음으로 접하게 되는 좌상단에 분기와 지역필터가 가능함을 언급
2. 캡션을 통해 간략한 기능과 표현하고자 하는 바에 대한 설명 삽입
3. '가입연도별 리뷰가 없는 숙소 비율' 그래프를 각 연도에 대한 비율로 정정하여 삽입(정보를 더 알맞은 형태로 표현하기 위함)
4. 연도별 필터를 삭제하고, 분기별 필터로 적용.
※ Join과 Union ※
UNION: 데이터셋을 가져다가 쌓는 것!
-데이터셋 두개가 컬럼 개수가 똑같아야 union 가능
eg)
db1 : 1~10 column, 100 row
db2: 1~10 column, 120 row
union db1 db2 → 1~10 columnm, 220 row
eg) 똑같은 컬럼을 가지고 있지만 연도만 다른 것
JOIN: 가장 많이 쓰는 것은 Left Join
데이터 양이 너무 커서 조인하면 다운될 경우
- 각각 따로 load 한 다음 혼합관계편집으로 엮어줄것.
- 추출을 다 했음에도 다시 추출하기 때문에, 렉이 많이 걸린다.
(정말 필요한 경우에만 쓰는 게 좋다)
* SQL 팁
select ~~(1~9까지 있을 때)
from ~~
group by 1,2,3,4,5,6,7,8,9
→이런식으로 하면 데이터의 중복 사라짐