1주 4일차 TIL 정리

1주 4일차의 주 내용은 파이썬 pandas를 활용한 데이터 핸들링과, 서울시 공공데이터를 활용한 실습이다.
※ 행을 열로 보내기: 데이터프레임.melt()

(실습기준데이터)

- 모든 열 melt: melt()
df.melt()
- 고정할 컬럼 지정해 melt: melt(id_vars=['컬럼명'])
# name 고정
df.melt(id_vars=['name'])
# name, kor 고정
df.melt(id_vars=['name','kor'])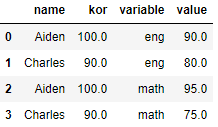
- 행으로 위치 변경할 열 지정: melt(value_vars=['컬럼명'])
# kor, eng
df.melt(value_vars=['kor','eng'])
- 컬럼명 변경하기: melt(var_name='컬럼명', value_name='컬럼명')
# subject, score
df.melt(value_vars=['kor','eng'],var_name='subject',value_name='score')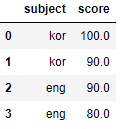
※ 열을 행으로 보내기: pivot
- 데이터프레임.pivot( index=인덱스로 사용할 컬럼, columns=컬럼으로 사용할 컬럼, values=값으로 사용할 컬럼 )
(실습기준데이터)

# name, subject, grade
df.pivot(index='name',columns='subject',values='grade')
# name, subject, [grade,score]
df.pivot(index='name',columns='subject',values=['score','grade'])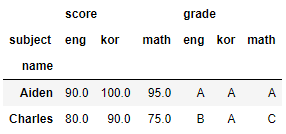
※ 행과 열 바꾸기: 데이터프레임.transpose()
df.transpose()
※ 피봇테이블로 데이터 집계: pd.pivot_table
- pd.pivot_table(데이터프레임, index=인덱스, columns=컬럼, values=집계할데이터, aggfunc=통계함수)
(실습기준데이터)
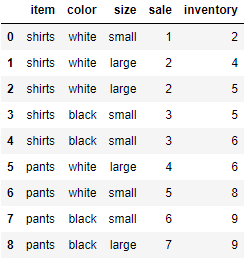
# [item,color], size별 재고 합계
# null값은 0으로 처리 (fill_value = 0)
df.pivot_table(index = ['item','color'],columns='size', values='inventory', aggfunc='sum',fill_value=0)
* aggfunc는 sum, mean, max, min 등이 있다.
※ 그룹 다루기
- df.groupby(그룹기준컬럼).통계적용컬럼.통계함수
- count() : 누락값을 제외한 데이터 수
- size() : 누락값을 포함한 데이터 수
- mean() : 평균
- sum() : 합계
- std() : 표준편차
- min() : 최소값
- max() : 최대값
- sum() : 전체 합
(실습기준데이터, df_titanic)

# 객실등급(Pclass)별 생존자 수
df2 = df_titanic.groupby('Pclass').Survived.sum().to_frame()
# 성별, 객실등급별 생존율
df0 = df_titanic.groupby(['Sex','Pclass']).Survived.mean().to_frame()
df0
- 그룹에 사용자 정의함수 적용하기: df.groupby(그룹기준컬럼).통계적용컬럼.agg(사용자정의함수,매개변수들)
# my_mean 함수 적용하기
def my_mean(values):
return sum(values)/len(values)
df.groupby(['Sex','Pclass']).Survived.agg(my_mean).to_frame()
- 그룹의 개별 오브젝트 출력:
데이터프레임.groupby(그룹기준컬럼).groups
데이터프레임.groupby(그룹기준컬럼).get_group(그룹인덱스)
# Pclass 그룹별 인덱스
df20.groupby('Pclass').groups
# Pclass 그룹 출력(1등석)
df20.groupby('Pclass').get_group(1)
*** 그래프에서 마이너스 폰트 깨지는 문제에 대한 대처 ***
mpl.rcParams['axes.unicode_minus'] = False
*** 폰트 지정하기 ***
plt.rcParams['font.family'] = 'NanumSquare'
*** 폰트 확인하기 ***
[f.name for f in fm.fontManager.ttflist if 'Nanum' in f.name]
※ 서울시 공공데이터 핸들링 ( 코로나19 현황 분석 )
*** 한글 csv 파일 깨질 때 ***
방법 1
파일이름 뒤에 comma 넣고 encoding='cp949' 입력
방법 2
엑셀로 연 후 다른 이름으로 저장 - CSV UTF-8(쉼표로 분리) 선택
방법 3
메모장으로 연 후 다른 이름으로 저장 - 인코딩에서 UTF-8(BOM)선택
- 실습데이터: 인기그룹데이터(코로나19)> 공공데이터 | 서울열린데이터광장 (seoul.go.kr)
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
1. 데이터 확인 및 전처리

- 불필요 컬럼 삭제
df = df.drop(columns=['환자번호','국적','환자정보','조치사항','이동경로','등록일','수정일','노출여부'])
- 자료형 변환
# 확진일 --> datetime
df['확진일'] = df['확진일'].astype('datetime64')
# 지역의 공백으로 발생하는 이중 중복 데이터 제거(공백 제거)
df['지역'] = df['지역'].str.strip()
# 지역, 상태 --> category (지역의 공백 제거)
df['지역'] = df['지역'].astype('category')
# 정보
df.info()
- 결측치 분석
df.isnull().sum()
(여행력에만 결측치 존재)
2. 구별 확진자 동향 파악
- 피봇테이블 만들기
# 확진일이 인덱스, 구가 컬럼, 확진자수(카운트값)가 밸류 / margins=True로 마지막 열에 총계 추가
df_gu = pd.pivot_table(df, index='확진일',columns='지역',values='연번',aggfunc='count', margins=True)
df_gu
3. 일별 추가확진자 동향
# All 행에서 마지막 열(All)을 제외하고 모든 데이터를 선별한다.
s_date = df_gu['All'][:-1]
# 서울시 일별 추가확진자가 많았던 순으로 보기
s_date.sort_values(ascending=False)
- 시각
# 서울시 일별 추가확진자 시각화
x = s_date.index
y = s_date.values
plt.plot(x,y)
plt.title('서울시 일별 추가확진자(2021.09.28)')
plt.xlabel('확진일')
plt.ylabel('추가확진자수')
plt.xticks(rotation=45)
plt.show()
4. 서울시 구별 누적확진자 비교
# 서울시 구별 누적확진자 많은 순으로 보기
s_gu = df_gu.loc['All'][:-1] # 데이터 행별로 가져오려면 loc
s_gu = s_gu.sort_values(ascending=False)# 서울시 구별 누적확진자 많은 순으로 시각화
x = s_gu.index
y = s_gu.values
plt.figure(figsize=(10,7))
plt.title('서울시 구별 누적확진자(2021.09.28)',size=20)
plt.xlabel('누적확진자수')
plt.ylabel('지역')
plt.barh(x,y)
plt.show()
5. 최근일 기준 지역별 추가 확진자
s_gu = df_gu.iloc[-2][:-1]
s_gu = s_gu.sort_values(ascending=False)x = s_gu.index
y = s_gu.values
plt.barh(x,y)
plt.show()
6. 최근월 접촉력에 따른 확진 건수 best 10
df[(df['확진일'].dt.year == 2021) & (df['확진일'].dt.month == 9)]['접촉력'].value_counts()[:10].to_frame()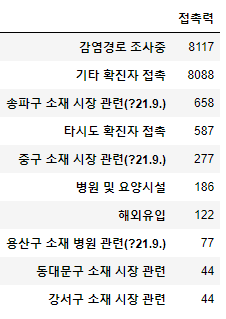
이상으로 1주 4일차의 TIL포스팅을 마치겠다.