1주 3일차 TIL 정리

1주 3일차의 주 내용은 파이썬의 Pandas 확장프로그램을 활용한 데이터 탐색방법이라 할 수 있다.
대부분의 내용이 생소했어서 오늘의 내용은 꽤나 많을 전망이다.
2일차에서 작성한 pandas의 데이터프레임과 시리즈부터 다시 한 번 보고 가자.
시리즈: 엑셀시트로 가정했을 때, 열 1개 (1차원 데이터)
데이터프레임: 엑셀시트로 가정했을 때, 시트 (2차원 데이터)
시리즈는 index와 value로 구성돼있다.
- index
# 시리즈의 index 가져오기
s.index
# 시리즈 인덱스 지정하기
s.index = ['name','hieght','footsize']
s
- value
# 시리즈의 value 가져오기
s.values
- 시리즈의 통계값 사용하기: 명령어(mean, min, max, median, std)를 사용해 value의 통계값을 구할 수 있다.
print('평균:',s2.mean())
print('최소값:',s2.min())
print('최대값:',s2.max())
print('중간값:',s2.median())
print('표준편차:',s2.std())
(describe를 활용해 요약통계 또한 볼 수 있다.)
s2.describe()
- 시리즈의 주요 메소드: 정렬, 인덱스 리셋, 교체, 데이터프레임으로의 전환 등이 가능하다.
# s3의 value 중 10을 5로 교체
s3 = s3.replace(10,5)
s3
# s3 정렬 (디폴트는 오름차순 : ascending=True)
s3.sort_values()
# s3.sort_values(ascending=False)
# s3을 데이터프레임으로 만들기
s3.to_frame()
# 시리즈 인덱스 새로 만들기
s.reset_index()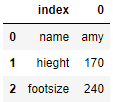
- 컬럼명으로 데이터 추출하기
# 시리즈 형태로 데이터 추출: 데이터프레임명['컬럼']
s_name = df['name']
s_name.head()
# 데이터프레임으로 추출하기: 데이터프레임[['컬럼명','컬럼명']]
# 'name','kor' 컬럼 데이터 추출하기
df_name_kor = df[['name','kor']]
df_name_kor.head(5)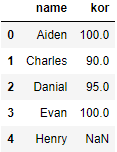
- 추출한 데이터 성질 확인
# 타입(시리즈/데이터프레임)의 확인: type
type(s_name)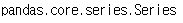
# series 의 크기가 어떤가?
# shape
s_name.shape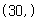
# 컬럼의 데이터타입 알아보기
df['math'].dtype
↑
s유무를 유의하도록 하자.
↓
# 데이터프레임의 자료형 확인
df.dtypes
- 조건에 따른 데이터 추출 (boolean index)
# kor 점수가 100점인 데이터 불린인덱스
df['kor'] == 100
- 위 값에 "데이터프레임명[ ]" 으로 감싸주면 True인 데이터만 노출.
# kor 점수가 100점인 데이터 추출
df[df['kor'] == 100]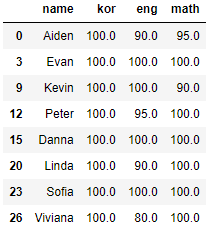
- 논리연산자의 사용: 논리연산자는 '&' , '|' ,'~', '^' 기호를 사용한다. 각 조건을 ()로 감싼다.
# 한 과목이라도 100을 받은 학생 추출
df[ (df.kor == 100) | (df.eng == 100) | (df.math == 100) ]
# kor의 값이 60~90인 학생의 name, kor 추출
df[ (df['kor']>=60) & (df.kor<=90) ] [['name','kor']]
# df['kor'] 혹은 df.kor 사용 여부 딱히 상관 무다음과 같이 뒤에 중괄호를 추가해 필요데이터만 표시할 수도 있다.

- 조건값 도출 (isin)
# 이름이 Amy, Rose인 데이터 추출
df[df['name'].isin(['Amy','Rose'])]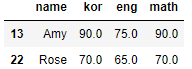
- null값 여부에 따른 추출(isnull, notnull)
# kor이 null인 데이터 추출
df[df.kor.isnull()]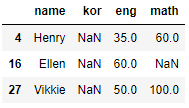
- 인덱스명을 기준으로 행 데이터 추출: 데이터프레임명.loc['인덱스']

(인덱스 형태로 추출하기)
# 인덱스가 i3인 행 추출하여 s1에 담기
s1 = df.loc['i3']
s1
(데이터프레임 형태로 추출하기)
(하나만 추출)
# 인덱스가 i3인 행을 데이터프레임 형태로 추출하기
df.loc[['i3']]
(여러 개 대상)
# 인덱스가 i1,i3,i5인 행 추출하기
df.loc[['i1','i2','i3']]
# 인덱스 i1,i3,i5의 name, kor
df.loc[['i1','i3','i5'],['name','kor']]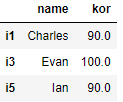
- 인덱스가 아닌 행 번호로 데이터 추출하기 데이터프레임명.iloc[행번호]
# 1,3,5번 행 추출하기
df.iloc[[1,3,5]]
(슬라이싱 또한 가능하다)
# 홀수 행번호의 데이터 추출하기
df.iloc[1::2]
- 맥플롯립 라이브러리를 활용한 그래프 그리기

x = ['a','b','c','d','e']
y = [1,3,2,10,7]plt.scatter(x,y,label='scatter') # 산점도
plt.bar(x,y,label='bar') # 막대그래프 (가로 막대그래프는 barh)
plt.plot(x,y,label='plot') # 선그래프
# label: 범례에 label달기
plt.title('Test Graph', size = 15)
plt.xlabel('x')
plt.ylabel('y')
plt.legend() #범례표시
plt.show()
(다른 예시)
# x축 y축 데이터 준비
x = df['name']
y = df['kor']plt.bar(x,y)
plt.xticks(rotation=90) # 하단 이름 글자 회전
plt.title('Scores', size=20)
plt.xlabel('name')
plt.ylabel('kor_score')
plt.show()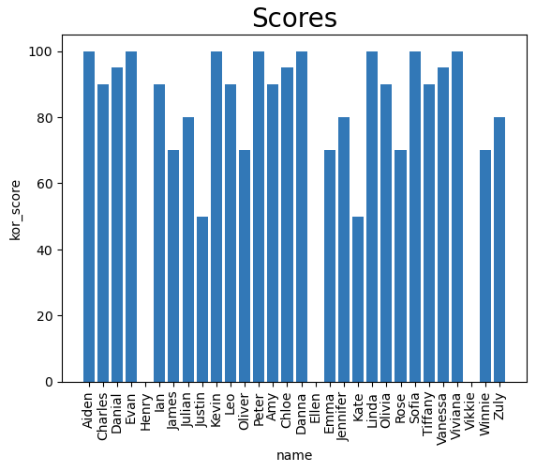
- 열 추가 : 데이터프레임[ '컬럼명' ] = 추가할 데이터
# sum 컬럼 추가
df['sum'] = df['kor']+df['eng']+df['math']
- 열 삭제: drop(columns = 삭제할 컬럼(들))
# no, sum 컬럼 삭제하기
df = df.drop(columns = ['no','sum'])
# df.drop(columns = ['no','sum'], inplace = True) → 이런 형태도 가능
- 컬럼명 한 번에 바꾸기: 데이터프레임.columns = 컬럼명리스트
df.columns = ['이름','국어','영어','수학']
- 특정 컬럼명 바꾸기
# 이름-->성명
df.rename(columns = {'이름':'성명'}, inplace = True)
- 마지막에 행 추가 : 데이터프레임.append(추가할 데이터) // ignore_index = True를 붙이면 인덱스 재지정
new_value = {'name':'Python','kor':80,'eng':90,'math':100}
df = df.append(new_value, ignore_index=True)
df.tail()
- 인덱스 지정하여 행 추가 (수정도 동일한 방법으로 이뤄짐)
# 인덱스 35, 34에 추가
df.loc[35] = ['aaa',70,80,90]
df.loc[34] = ['bbb',80,90,100]
df.tail()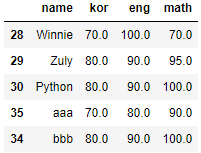
- 행 삭제하기: 데이터프레임.drop(index = ['삭제할인덱스명']
# 34,35행 삭제
df = df.drop(index=[34,35])
# df.drop(index=[34,35],inplace=True) 동일한 결과
df.tail()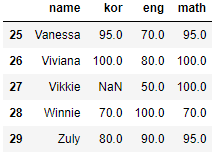
- 인덱스 이름 변경하기
(전체 인덱스)
df.index = range(100,3100,100)
df.head()
(특정 인덱스)
# 100-->'a', 200-->'b'
df = df.rename(index = {100:'a', 200:'b'}
df.head()
- 함수의 적용: 컬럼.apply(함수명) / 컬럼.apply(함수명, 매개변수명=매개변수값)
# 선택한 점수에 n점 더하기. 100점이 넘을 수 없다.
def plus_n(x,n):
score = x+n
if score > 100:
score = 100
return score
# df['eng']의 모든 점수에 n점 더하기. 100점이 넘을 수 없다.
df_copy.eng = df['eng'].apply(plus_n, n=1)
df_copy.head()
(axis=1 을 적용하면 행단위로 함수가 적용된다.(기본값: axis=0, 열단위))
# 합계 구하기
def get_sum(x):
return x.sum()
# 학생 별 점수 합계
df['sum'] = df.apply(get_sum, axis = 1)
df
- 결측치 삭제하기: dropna
import pandas as pd
import numpy as np
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],
columns=list('ABCD'))
df
(결측치가 존재하는 모든 행 삭제)
df.dropna()
(결측치가 존재하는 모든 열 삭제)
df.dropna(axis=1)
- 결측치 대치하기: fillna(값)
(특정값으로 채우기)
# 0으로 채우기
df.fillna(0)
(평균값으로 채우기)
# 평균값으로 채우기(컬럼별 평균값으로 채워진다.)
df.fillna(df.mean())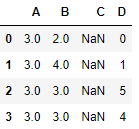
(이전 값으로 채우기)
df.fillna(method='ffill')
(다음 값으로 채우기)
df.fillna(method='bfill')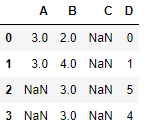
(컬럼별로 대치할 값을 지정)
df.fillna({'A':0,'B':1,'C':2})
- 자료형 변환: astype('자료형')
# 실수형으로 변환
df = df.astype('float64')
# 문자열로 변환
df = df.astype('str')
# 정수형으로 변환 (문자열에서 정수로 가려면 float거쳐야 한다)
df = df.astype('float').astype('int')
- 자료형이 혼합된 컬럼을 숫자로 변경: numeric(컬럼, errors=' ignore / coerce / raise ')

# ignore:숫자료 변경할 수 없는 데이터가 있으면 작업하지 않음
pd.to_numeric(s2, errors='ignore')
# coerce:숫자로 변경할 수 없는 값이 NaN으로 설정
pd.to_numeric(s2, errors='coerce')
# raise : 숫자로 변경할 수 없는 값이 있으면 에러발생(default)
pd.to_numeric(s2, errors='raise')
# → 기본값. 에러남- 시계열 데이터로 변경: pd.to_datetime('컬럼')
df['출생'] = pd.to_datetime(df['출생'])
# 둘 다 결과는 같다.
df['출생'] = df['출생'].astype('datetime64')
- 카테고리형 다루기: 기본 데이터타입 외 카테고리로 따로 지정해 관리. (용량 ↓, 효율)
# 평균점수 average 컬럼 추가
df['average'] = round((df['kor'] + df['eng'] + df['math'])/3,1)
# 평균점수에 따른 grade 컬럼 추가
def get_grade(x):
if x>=90:
return 1
elif x>=80:
return 2
elif x>=70:
return 3
elif x>=60:
return 4
else:
return 5
df['grade'] = df['average'].apply(get_grade)
df.head()

# 자료형 변환으로 카테고리형으로 변환
df['grade'] = df['grade'].astype('category')
df['grade'].dtypes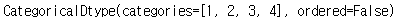
(카테고리 이름 바꾸기)
df['grade'].cat.categories = ['a','b','c','d']
df.head()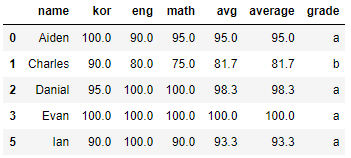
(누락된 카테고리 바꾸기)
df['grade'] = df['grade'].cat.set_categories(['a','b','c','d','f'])
df.grade.dtypes
- 시계열자료 다루기
# 출생 컬럼의 연도
df['출생'].dt.year
# 출생 컬럼의 달
df['출생'].dt.month
# 출생 컬럼의 일자
df['출생'].dt.day
- 날짜 계산하기
# 사망나이 컬럼 만들기
df['사망나이'] = df['사망'].dt.year - df['출생'].dt.year
df
- 요일, 월 이름 노출: strftime(' %a / %A / %w / %b / %B ')
(요약요일 / 긴 요일 / 숫자요일(0~6) / 요약 월 / 긴 월)
# 출생월 컬럼 추가하기
df['출생월'] = df['출생'].dt.strftime('%b')
df
- datetime 자료형을 인덱스로 만들어 사용

# 출생 컬럼을 인덱스로 만들기
df.index = df['출생']
# 1955년 2월 출생 데이터 추출하기
df.loc['1955-02']

- 데이터프레임 행을 기으로 연결하기: pd.concat([ '데이터프레임 리스트' ])

# 샘플 데이터
df1 = pd.DataFrame([['a', 1], ['b', 2]], columns=['letter', 'number'])
df2 = pd.DataFrame([['c', 3], ['d', 4]], columns=['letter', 'number'])
df3 = pd.DataFrame([['e', 5, '!'], ['f', 6, '@']], columns=['letter', 'number', 'etc'])(컬럼명 기준으로 연결하기)
# 컬럼명 기준으로 연결하기
df_rowconcat = pd.concat([df1,df2,df3])
df_rowconcat
( 컬럼명 기준 연결, 공통된 컬럼만 남기기 (inner join) )
df_rowconcat = pd.concat([df1,df2,df3],join='inner', ignore_index=True) # 마지막은 인덱스 재지정
df_rowconcat
# inner join!
- 데이터프레임 열을 기준으로 연결하기
# 샘플 데이터
df4 = pd.DataFrame({'age':[20,21,22]},index = ['amy','james','david'])
df5 = pd.DataFrame({'phone':['010-111-1111','010-222-2222','010-333-3333']},index = ['amy','james','david']
)
df6 = pd.DataFrame({'job':['student','programmer','ceo','designer']},index = ['amy','james','david','J']
)(인덱스 기준으로 연결하기)
df_column_concat = pd.concat([df4,df5,df6],axis=1)
df_column_concat
( 인덱스 기준 연결, 공통된 컬럼만 남기기 (inner join) )
df_column_concat = pd.concat([df4,df5,df6],axis=1,join='inner')
df_column_concat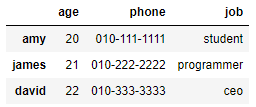
- 공통된 열을 기준으로 연결: pd.merge(left, right, on, how='연결방법')
# name을 기준으로 연결, how = 'inner'(default)
pd.merge(df7,df8,on='name')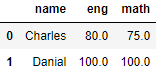
# how = 'outer'
pd.merge(df7,df8,on='name', how ='outer')
# outer join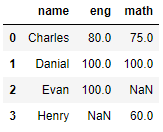
(왼쪽 데이터프레임 기준으로 연결)
pd.merge(df7,df8,on='name', how ='left')
# left outer join
(오른쪽 데이터프레임 기준으로 연결)
pd.merge(df7,df8,on='name', how ='right')
# right outer join
하루 평:
모르는 것만 정리하자고 했지만, Pandas를 접하는 것은 처음이라 거의 모든 내용을 정리하게 됐다. 정리하면서의 목적은 구글링 대신 내 블로그를 찾을 수 있게 하자는 것. 익숙해질 수 있게 자주 들어와서 가볍게 보며 복습해야겠다.
이상으로 1주 3일차의 TIL포스팅을 마치겠다.