-
2주 3일차 TIL 정리웅진 STARTERS 부트캠프 2023. 2. 15. 17:43

2주 3일차는 파이썬 시각화를 마무리하고, SQL에 본격적으로 들어가는 시간이었다.
SQL의 기초는 어느 정도 알고 있던 만큼, 복습하며 기억을 되살릴 수 있는 시간이었다.
※ 시도별 아파트 매매가 현황 ※
1. 데이터 수집
- 국토교통부 실거래가 공개시스템
http://rtdown.molit.go.kr/
http://rtdown.molit.go.kr/
rtdown.molit.go.kr
1-1. 데이터프레임 지정
df = pd.read_csv('../data/아파트(매매)__실거래가_20211122131854.csv',encoding='cp949') df
2. 데이터 전처리
2-1. 해지사유 발생일 데이터가 존재하면 삭제 (완료데이터만 분석을 위함)
# 해제사유 발생일이 존재하는 데이터 삭제 df = df.drop(index = df[df['해제사유발생일'].notnull()].index) df[df['해제사유발생일'].notnull()]
데이터가 없어 컬럼만 뜨는 것을 볼 수 있다. 2-2. 사용할 컬럼만 추출 ( 시군구, 전용면적, 거래금액 )
df = df[['시군구','전용면적(㎡)','거래금액(만원)']] df
2-3. 자료형 확인 및 변경
# 전용면적 : int(소수점 무시) df['전용면적(㎡)'] = df['전용면적(㎡)'].astype('int64') # 거래금액 : int( , 제거한 후 int로 변경) df['거래금액(만원)'] = df['거래금액(만원)'].str.replace(',','').astype('int64') df.dtypes
3. 시도 컬럼 추가
df['시도'] = df['시군구'].str.split(' ').str[0] df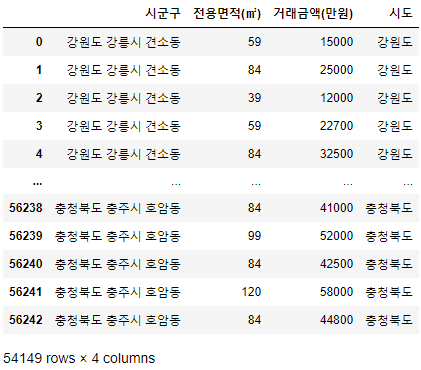
4. 분석할 전용면적 고르기 (가장 많은 데이터로 선별)
df['전용면적(㎡)'].value_counts()
* 84m^2이 가장 많으므로, 해당 데이터를 사용.
df_84 = df[df['전용면적(㎡)']==84].copy() df_84
5. 시도별 평균, 최대, 최소, 중간값 추출
# 시도별 평균값 df_84_mean = df_84.groupby('시도')['거래금액(만원)'].mean() # 시도별 최대값 df_84_max = df_84.groupby('시도')['거래금액(만원)'].max() # 시도별 최소값 df_84_min = df_84.groupby('시도')['거래금액(만원)'].min() # 시도별 중간값 df_84_median = df_84.groupby('시도')['거래금액(만원)'].median() # 편리한 관리를 위해 하나의 데이터프레임에 합치기 df_84_price = pd.concat([df_84_mean,df_84_max,df_84_min,df_84_median],axis=1) # 전부 거래금액(만원)으로 표시돼있는 컬럼명 바꾸기 df_84_price.columns=['평균','최대','최소','중간'] df_84_price.head(1)
5-1. 데이터 순서 정렬, 다듬기
# 데이터를 평균이 큰 순으로 정렬하기 df_84_price = df_84_price.sort_values('평균',ascending=False) # 평균값을 소수점 한 자리까지 표시하도록 하기 df_84_price['평균'] = round(df_84_price['평균'],1)6. 시각화
4개의 그래프를 짝지어 나열해야 하므로, x인덱스를 일단 숫자로 설정해준 후 그래프의 위치 설정이 끝나면 레이블을 달아준다.
# x 인덱스를 숫자로 지정 x_index = np.arange(1,len(df_84_price)+1) x_index # 캔버스 사이즈 설정 plt.rcParams['figure.figsize']=(15,5) # 최대, 평균, 중간, 최소 순으로 bar그래프 그리기(값이 큰 순서) plt.bar(x_index-0.3 # index - 0.3이 중심에 위치한다. ,df_84_price['최대'] ,width=0.2 # 두께가 0.2이다. ,label='평균') plt.bar(x_index-0.1 # index - 0.1이 중심에 위치한다. ,df_84_price['평균'] ,width=0.2 ,label='최대') plt.bar(x_index+0.1 # index + 0.1이 중심에 위치한다. ,df_84_price['중간'] ,width=0.2 ,label='중간') plt.bar(x_index+0.3 # index + 0.3이 중심에 위치한다. ,df_84_price['최소'] ,width=0.2 ,label='최소') plt.xticks(x_index # x의 레이블을 다시 df_84_price의 인덱스(시도)로 설정한다. ,labels = df_84_price.index ,rotation=-45) plt.ylabel('매매가(만원)') plt.grid(axis='y',ls=':') plt.legend() plt.title('2021년 8월 시도별 아파트 매매가 현황(84㎡)') plt.show()
※ SQL 기초 정리 ※
1. 데이터베이스: 데이터를 모아두기 위한 방법 및 저장소
2. DBMS: 데이터베이스를 관리/운영하는 역할을 하는 시스템과 응용 프로그램
3. Schema
- 물리적 스키마: DBMS에 저장되는 공간 (DATABASE)
- 논리적 스키마: 저장 공간의 영역
4. Table
- 하나 이상의 열로 구성
- 데이터베이스를 이루는 구성요소
5. SQL
- SQL 언어 개념: 관계형 데이터베이스를 사용할 때 RDBMS에게 보내는 요청, ' QUERY ', ' 질의 '
- DML(Data Manipulation Language): 데이터 조작어, 검색 및 수정 기능.
eg) SELECT, INSERT, UPDATE, DELETE, MERGE
- DDL(Data Defination Language): 데이터 구조어, 생성, 변경, 삭제 등
eg) CREATE, ALTER, DROP, RENAME
- DCL(Data Control Language): 데이터 권한 관리 및 트렌잭션
eg) GRANT, REVOKE
6. 데이터 생성과 관련한 부분은 이전의 게시글과 동일하다.
https://woodenstella.tistory.com/1
서점 Data 생성 연습
상황을 가정해 데이터를 입력해보자. 서점에서 데이터를 입력하는 방식을 기준으로, 크게는 보유 서적, 멤버십 고객, 거래 내역을 기준으로 데이터를 입력하고자 한다. 입력되는 데이터는 다
woodenstella.tistory.com
7. 테이블 생성 시의 제약 조건
https://woodenstella.tistory.com/4
테이블 생성 시의 제약조건
이번 게시글에선 테이블 생성 시의 제약조건에 대해 조금 알아보고자 한다. 1. null값 배제(필수적인 정보의 확보) 학교에서 학생을 입학시킬 때를 예시로 들어보자. 이때 데이터로 입력해야
woodenstella.tistory.com
8. ALTER문으로 테이블 컨트롤하기
https://woodenstella.tistory.com/8
ALTER문으로 테이블 컨트롤하기
이번 게시글에선 ALTER문을 이용한 테이블의 속성과, 속성에 대한 제약 변경 등에 대해 알아보고자 한다. 이에 앞서 새로운 테이블 newBook을 만들어 조작해보도록 하자. create table newBook( bookid
woodenstella.tistory.com
9. 테이블이나 컬럼의 속성을 출력하는 명령어: DESCRIBE
describe BookLibrary;
describe BookLibrary.bookname;
※ 그룹 토의 및 멘토링 내용 정리 ※
1. 멘토링에서 질문한 내용:
Q. 이 상황에서 첫번째 사진처럼 xlabel을 넣지 않고 boxplot의 설정으로 가서 labels를 입력해줘야 하는 이유가 무엇인지 궁금합니다!
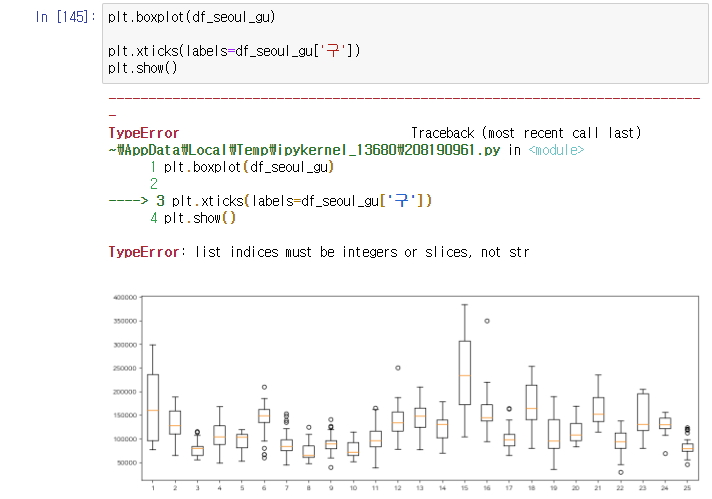

A. 박스플롯의 x축은 엄밀히 말해 x축이라기보단 그래프명에 가깝다. 따라서, x축의 개념이 아니기 때문에 xticks로 설정할 수 없다. 박스플롯의 그래프 이름을 달아준 것이고, 그걸 x축에 표시할 뿐이다.
2. 그룹 토의 내용
- 모두 SQL을 공부해본 경험이 있어 특별히 토의할 내용이나 공유할 내용은 없었지만, 팀원이 파이썬에서 csv 파일을 불러오는 중 일부 파일의 인코딩이 제대로 이루어지지 않아 한글이 깨지는 현상이 있었고, 이를 해결하려 해보았지만 실패했다. 추후 파일을 다시 다운로드 받아 인코딩설정을 하니 정상적으로 복구되었고, 다운로드상의 문제였던 것으로 추정된다.
'웅진 STARTERS 부트캠프' 카테고리의 다른 글
2주 5일차 TIL 정리 (4) 2023.02.17 2주 4일차 TIL 정리 (0) 2023.02.16 2주 2일차 TIL 정리 (0) 2023.02.14 2주 1일차 TIL 정리 (0) 2023.02.13 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화 직무(태블로) 1주차 학습일지 (0) 2023.02.12 - 국토교통부 실거래가 공개시스템